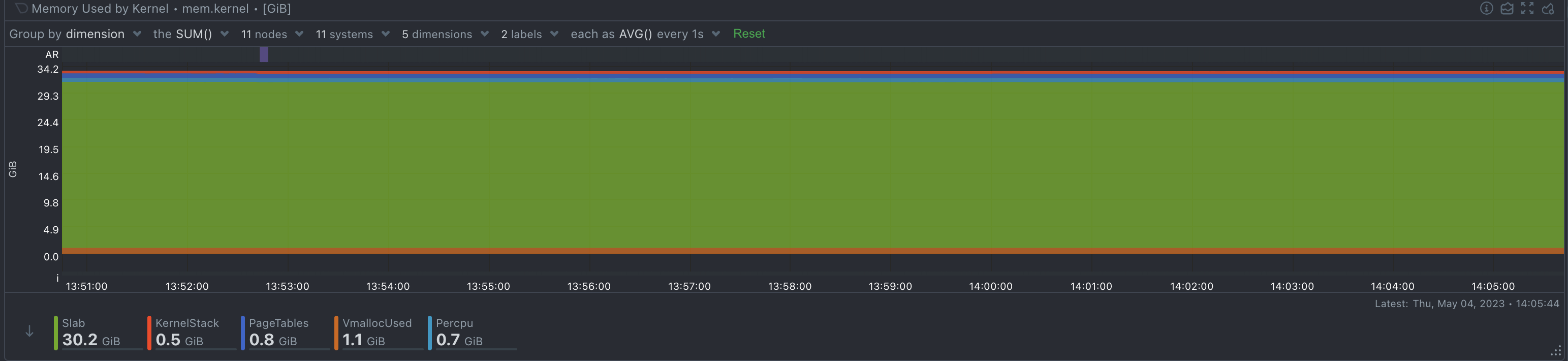
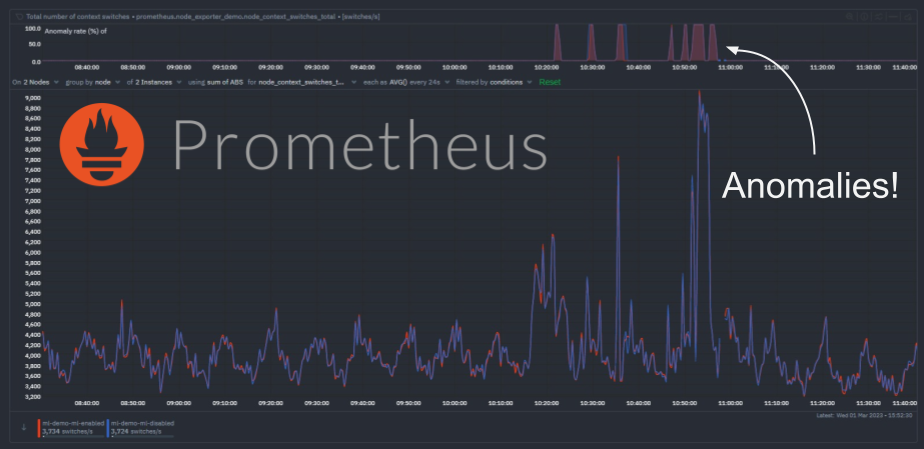
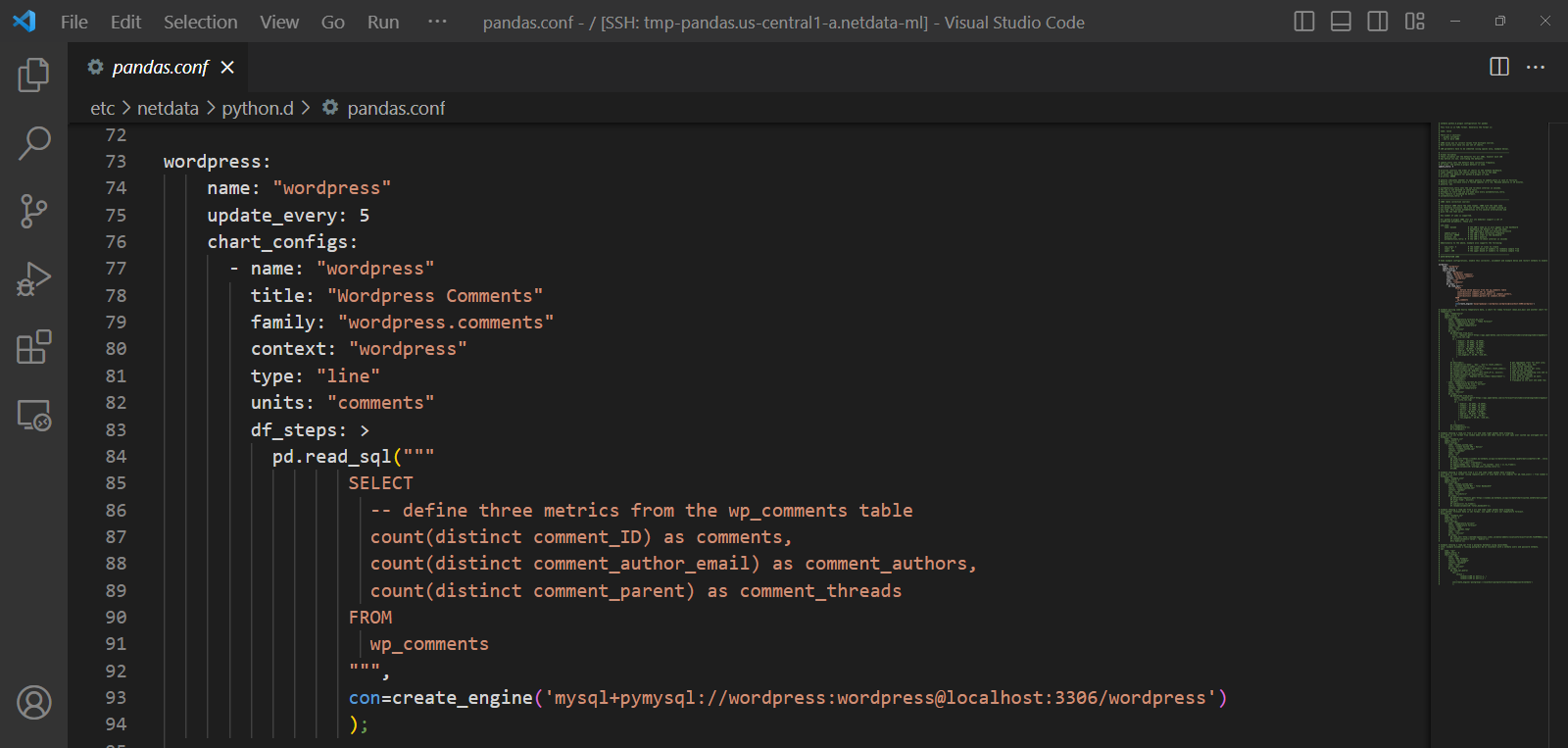
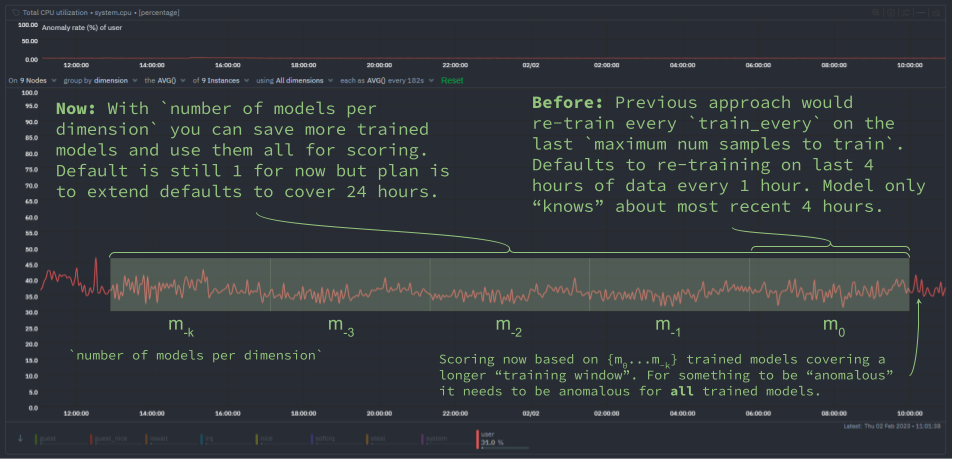
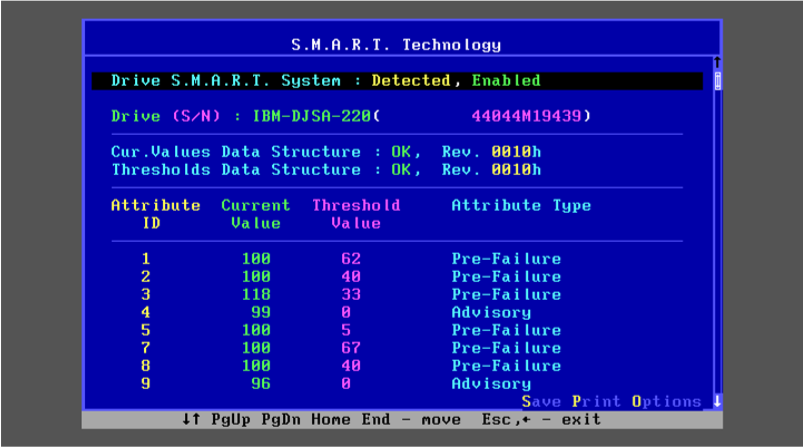
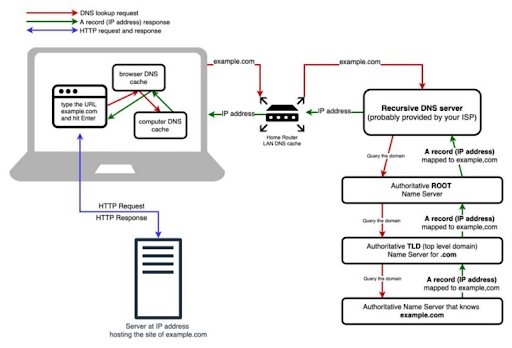
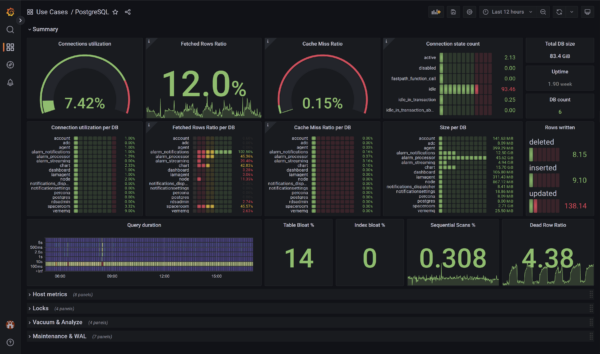
System operators know the drill: as the complexity of systems scales, so does the deluge of logs. Traditionally, taming this relentless tide demands a concoction of costly tools and laborious configurations—until now. The dynamic duo of systemd-journal and Netdata is revolutionizing log management, turning what was once a Herculean task into a streamlined, powerful, and surprisingly straightforward process.
System Operators: Unlock Log Management Mastery with systemd-journal and Netdata
· 7 min read

Technical Product Manager