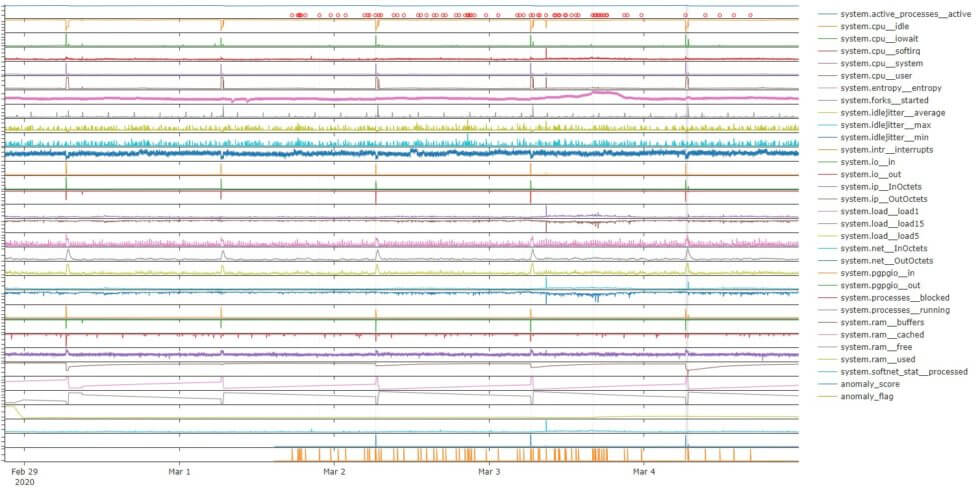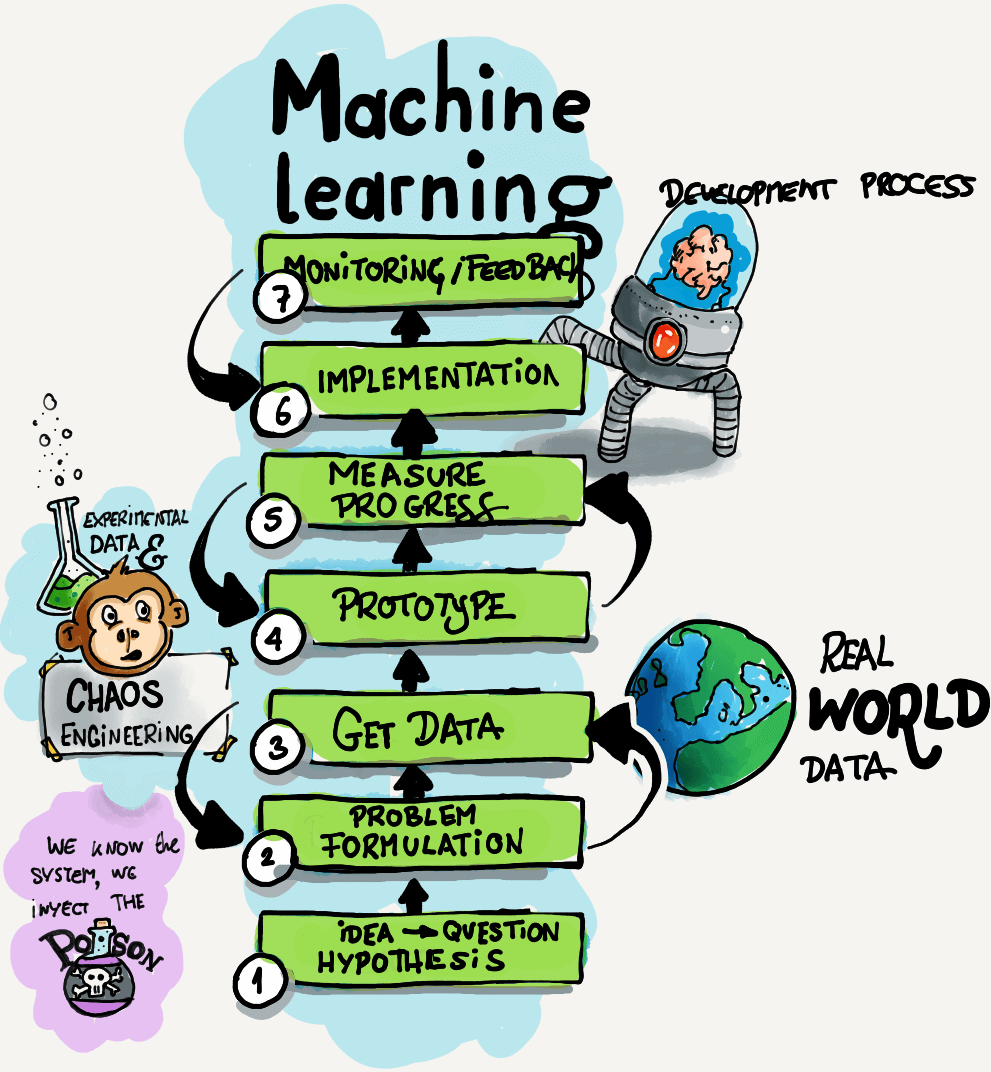
Netdata contributors have greatly influenced the growth of our company and are essential to our success. The time and expertise that contributors volunteer are fundamental to our goal of helping you build extraordinary infrastructures. We highly value end-user feedback during product development, which is why we’re looking to involve you in progressing our machine learning (ML) efforts! As we are continually looking for ways to improve and enhance Netdata, we are starting to explore how we can leverage machine learning to introduce new product features. Our main focus at the moment is around automated anomaly detection. This is a really interesting and challenging problem (high volume, high dimensional data, lack of ground truth labels, and so on), but we should be able to use some of the metrics monitored by Netdata to deliver new, awesome product features and user experiences (AI is the new electricity, after all 😃). However, developing ML-driven product features is quite different than traditional software development (see steps 1 to 7 in the picture above). Mainly, this is because you never really know what specific data transformations, problem formulation, and sets of algorithms will work best in advance. (Here is a good article explaining things, and if you really want to go down a rabbit hole, check out this Stack Overflow question and this Quora thread). Ideally, you first need to prototype your solution “in the lab” on some data you have already collected and do a few iterations of data → problem formulation → prototype. This process gives you a level of confidence in what you are doing (and some data to back it up) to move on to the even-more-complicated step of going from prototype to production. At Netdata, we are currently trying to get to step 4, where we can first prototype some solutions on real-world data and come up with ways to measure progress.