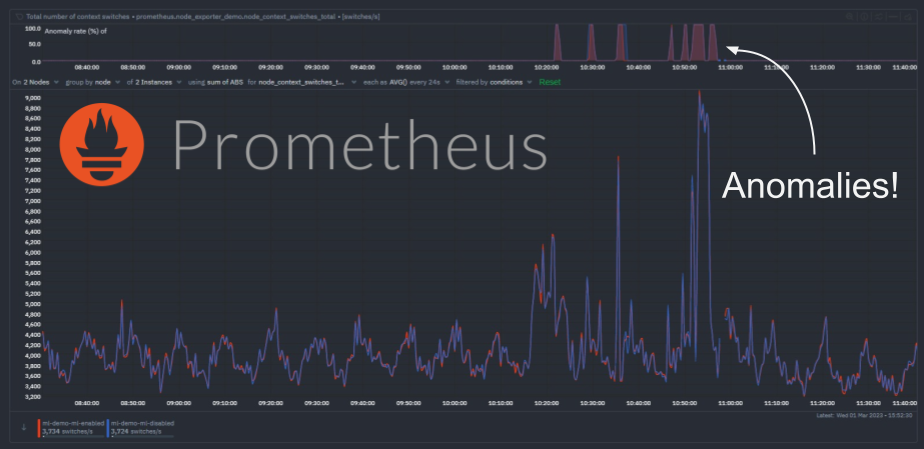
Context switching is the process of switching the CPU from one process, task or thread to another. In a multitasking operating system, such as Linux, the CPU has to switch between multiple processes or threads in order to keep the system running smoothly. This is necessary because each CPU core without hyperthreading can only execute one process or thread at a time. If there are many processes or threads running simultaneously, and very few CPU cores available to handle them, the system is forced to make more context switches to balance the CPU resources among them.
Context switching is an essential function of any multitasking operating system, but it also comes at a cost. The whole process is computationally intensive, and the more context switches that occur, the slower the system becomes. This is because each context switch involves saving the current state of the CPU, loading the state of the new process or thread, and then resuming execution of the new process or thread. This takes time and consumes CPU resources, which can slow down the system.
The impact of context switching on system performance can be significant, especially in systems with many processes or threads running simultaneously.